Introduction
Duplicate content is a serious concern for B2B SaaS companies aiming to enhance their online visibility. It refers to blocks of content that appear in more than one place on the internet. While this may not seem harmful, search engines penalize websites with duplicate content because it can confuse users and make it harder to determine which page to rank for a particular search query.
For B2B SaaS companies, duplicate content can negatively impact SEO efforts, leading to lower search rankings and reduced organic traffic. Additionally, it can diminish brand credibility and user trust. Therefore, it’s essential for B2B SaaS businesses to understand why duplicate content is problematic and take steps to address it. By creating unique and valuable content, businesses can improve their SEO performance and enhance their online presence.
What is duplicate content?
Duplicate content refers to blocks of content that are found in more than one location on the internet. This can occur within a single website or across multiple websites. Duplicate content can be problematic for search engines because they strive to provide users with the most relevant and diverse search results. When search engines encounter duplicate content, they may have difficulty determining which version to include or prioritize in their search results.
This can lead to lower rankings for pages with duplicate content or, in some cases, removal from search results altogether. Duplicate content can also create confusion for users, as they may encounter the same content in different places, which can diminish the credibility and trustworthiness of the website.
Types of duplicate content in SEO
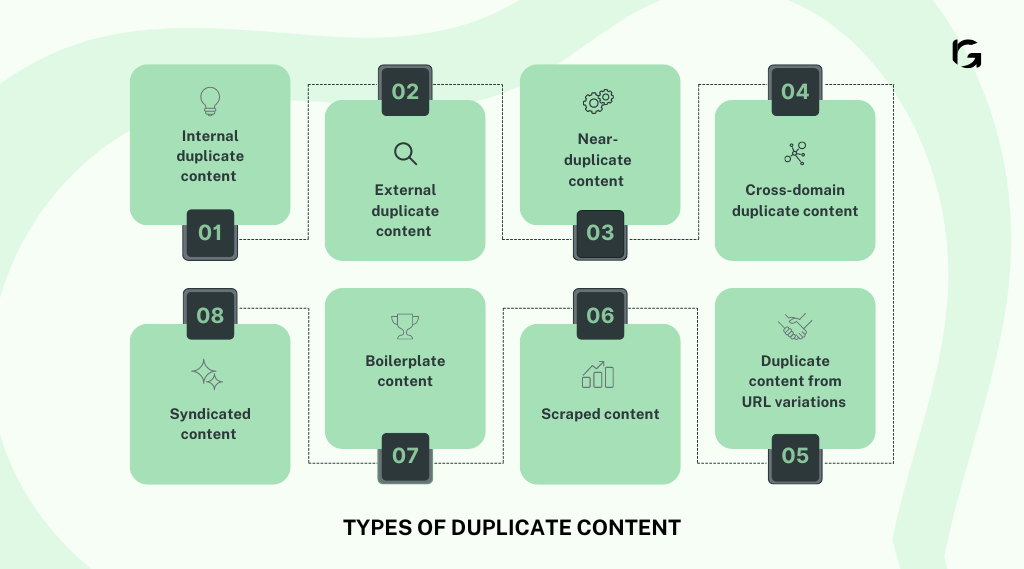
Duplicate content in SEO can take various forms, each with its own implications for search engine rankings and user experience. Understanding these different types is important for reducing their negative effects on how your website shows up in searches and how users experience your site.
1. Internal duplicate content
This occurs when the same content appears on multiple pages within the same website. It can happen unintentionally, such as when a product is listed in multiple categories, or intentionally, such as boilerplate text in footers or sidebars.
2. External duplicate content
External duplication happens when the same content is found on multiple websites. This can occur due to content scraping, where websites copy content from others without permission, or when websites syndicate content.
3. Near-duplicate content
Near-duplicate content is content that is very similar but not identical. This can occur when websites publish multiple versions of the same content, such as printer-friendly pages or pages with tracking parameters.
4. Cross-domain duplicate content
This type of duplication occurs when the same content is present on different domains. It can happen unintentionally, such as when websites have multiple domains pointing to the same content, or intentionally, such as when content is syndicated across different domains.
5. Duplicate content from URL variations
URL parameters, such as tracking codes or session IDs, can create duplicate content issues. Search engines may see these variations as separate pages with duplicate content.
6. Scraped content
Scraped content is copied from other websites without permission. Search engines penalize sites that use scraped content, as it provides no value to users.
7. Boilerplate content
Boilerplate content is generic, repetitive content that appears on multiple pages of a website, such as headers, footers, and navigation menus. While not always harmful, excessive use of boilerplate content can lead to duplicate content issues.
8. Syndicated content
Syndicated content is content that is published on multiple websites with permission. While syndicated content is not inherently bad, it can lead to duplicate content issues if not managed properly.
Understanding these types of duplicate content can help you identify and address duplication issues on your website, improving your SEO performance and user experience.
What is the impact of duplicate content on SEO?
The impact of duplicate content on SEO can be particularly detrimental due to the competitive nature of the industry and the necessity to establish credibility, differentiation, and visibility. Duplicate content poses significant challenges for B2B SaaS companies, impacting their search engine rankings, user experience, and overall online presence.
- Duplicate content can confuse search engines, making it difficult for them to decide which version of the content to display in search results.
- Search engines may penalize websites with duplicate content by lowering their rankings in search results.
- Duplicate content can also confuse users, leading to a poor user experience.
- By avoiding duplicate content and creating unique, high-quality content, you can improve your SEO performance and increase your website’s visibility in search results.
How to avoid duplicate content

Avoiding duplicate content is crucial for SEO. Here are some actionable tips to help you steer clear of duplicate content issues and improve your website’s search engine performance:
1. Create unique and valuable content:
Create original and valuable content that offers unique insights, perspectives, or solutions to your audience’s needs. Unique content stands a better chance of ranking higher in search results and engaging users.
2. Canonicalization
Use canonical tags to specify the preferred version of a page when duplicate or highly similar content exists across multiple URLs. This informs search engines about the primary version of the content to index and rank, consolidating link equity and avoiding confusion.
3. 301 Redirects
Implement 301 redirects to direct users and search engines to the canonical version of a URL. This method is particularly useful when merging pages or when different URLs lead to the same content. Redirects pass the SEO value from the duplicate page to the preferred one.
4. Consolidate similar content
Consolidating similar content involves merging or combining overlapping content into a single authoritative page. This approach helps prevent dilution of SEO authority across multiple pages and provides users with a comprehensive and valuable resource. For example, if you have multiple blog posts covering similar topics, you could consolidate them into a single, more in-depth article.
5. Manage URL parameters
Managing URL parameters is important for handling dynamic URLs that can generate multiple URLs for the same content. Google’s URL Parameter Tool in Search Console allows you to specify which parameters should be ignored or consolidated, helping to prevent duplicate content issues.
6. Unique meta tags and titles
Having unique meta tags, such as meta descriptions and titles, for each page is essential. This ensures that search engines can distinguish between different pages’ content in search results. Unique meta tags also help prevent confusion among users and improve click-through rates.
7. Syndication with attribution
When syndicating content, it’s crucial to provide proper attribution to the original source and use canonical tags. This not only gives credit to the original creator but also prevents search engines from treating syndicated content as duplicate. By following these practices, you can enhance your website’s SEO performance and provide a better user experience.
Implementing these best practices not only helps prevent duplicate content issues but also contributes to a stronger SEO foundation, improved search engine rankings, better user experience, and a more authoritative online presence. Regular monitoring and adherence to these strategies ensure a website remains optimized and avoids potential penalties from search engines.
5 Reasons for accidental duplicate content
Accidental duplicate content can be detrimental to your website’s SEO efforts, potentially leading to lower search engine rankings. Here are five common reasons for accidental duplicate content and how to avoid them:
1. URL parameters
URLs with tracking parameters or session IDs can create multiple versions of the same content. Search engines may treat these variations as separate pages with duplicate content. To avoid this, use canonical tags to specify the preferred URL for indexing. For example, if your website has URLs like example.com/page?utm_source=abc and example.com/page?utm_source=xyz, you can use a canonical tag to indicate that example.com/page is the preferred URL.
2. WWW vs. Non-WWW Versions
Having both “www” and “non-www” versions of your website can lead to duplicate content issues. Search engines may index both versions, seeing them as separate sites with duplicate content. To address this, choose one version (either “www” or “non-www”) as the preferred version and set up a 301 redirect from the non-preferred version to the preferred one.
3. HTTP vs. HTTPS
If your website is accessible via both HTTP and HTTPS, search engines may view these as separate sites with duplicate content. Ensure that all URLs redirect to the secure HTTPS version to avoid duplicate content issues.
4. Printer-friendly pages
Printer-friendly versions of your web pages, while useful for users, can create duplicate content. Search engines may index both the original page and the printer-friendly version, seeing them as duplicate content. To address this, use the rel=”canonical” tag to indicate the original page as the preferred version for indexing.
5. Pagination
Websites that use pagination to split long articles or product listings into multiple pages can inadvertently create duplicate content. Search engines may view each paginated page as a separate page with duplicate content. To avoid this, use rel=”next” and rel=”prev” tags to indicate the relationship between paginated pages, helping search engines understand that the paginated pages are part of a series and not separate pages with duplicate content.
By addressing these common causes of accidental duplicate content, you can improve your website’s SEO performance and provide a better user experience.
How to identify duplicate content
Duplicate content can harm your website’s SEO efforts, as search engines may penalize sites with duplicate content by lowering their rankings. Here’s how to find and address duplicate content on your website:
1. Use google search console
Google Search Console (GSC) is a free tool that helps you check if all your web pages are indexed by Google. It also identifies any pages that aren’t indexed and provides reasons for why this might be the case, including issues with duplicate content.
2. Utilize SEO tools
Tools like Screaming Frog, SEMrush, and Ahrefs can help you identify duplicate content by crawling your website and flagging pages with identical or very similar content.
3. Manually check content
Review your website’s content manually to identify pages that have identical or nearly identical content. Pay attention to product descriptions, blog posts, and other content that may have been duplicated.
Conclusion
Understanding and addressing duplicate content is crucial for maintaining a strong online presence. By identifying and rectifying duplicate content issues, you can improve your website’s SEO performance, enhance user experience, and establish your website as a reliable source of information.
Remember, implementing best practices such as using canonical URLs and creating original, high-quality content is not just about SEO; it’s about providing value to your audience. A well-optimized website not only ranks better in search engine results but also builds trust with visitors, leading to increased engagement and conversions.
If you’re unsure about how to tackle duplicate content or need assistance with your website’s SEO strategy, don’t hesitate to reach out to us at Revvgrowth. We’re here to help you navigate the complexities of SEO and create a successful online presence.